
SkillCorner Open Data #1: La visualización de los datos
.
.png)

Heading
En SkillCorner, creemos que la comunidad analítica avanza cuando los datos son accesibles y fáciles de utilizar. Con la serie SkillCorner Open Data, nuestro objetivo es proporcionar a analistas, estudiantes y aficionados recursos que les permitan adquirir experiencia práctica con los mismos datos que informan la toma de decisiones en los equipos profesionales.
La serie se centrará en los flujos de trabajo que se utilizan en el análisis moderno del fútbol. Cada cuaderno de trabajo mostrará un enfoque analítico específico que utiliza los datos abiertos de SkillCorner de la temporada 2024/25 de la A-League australiana.
El primer cuaderno de trabajo de la serie se centra en una plantilla de visualización de datos creada con la biblioteca SkillCorner Viz. Las visualizaciones son una parte fundamental a la hora de comunicar los conocimientos en el fútbol y la habilidad de crear gráficos claros y coherentes es imprescindible para un analista.
Este cuaderno muestra cómo importar las bibliotecas necesarias, cargar los datos, normalizar las métricas y crear tu primera visualización de datos.
1 - Importar las bibliotecas necesarias
El primer paso es abrir un cuaderno de Google Colab, lo cual puedes hacer directamente desde tu cuenta de Google Drive.
Una vez creado el cuaderno, ejecuta el bloque de código que aparece a continuación para instalar e importar la biblioteca de SkillCorner.
# Instalar las bibliotecas necesarias
!pip install skillcornerviz
!pip install skillcorner
# Importar las plantillas de visualización
from skillcornerviz.standard_plots import bar_plot as bar
from skillcornerviz.standard_plots import scatter_plot as scatter
from skillcornerviz.standard_plots import swarm_violin_plot as svp
from skillcornerviz.standard_plots import radar_plot as rad
2 - Cargar los datos físicos
El siguiente paso es crear un dataframe (df) con filas y columnas. Para ello, primero debemos cargar los datos físicos almacenados en un archivo CSV de nuestro repositorio de datos abiertos de GitHub.
Hay dos formas de acceder al archivo. La primera es crear una bifurcación del repositorio si estás trabajando en un entorno local como VS Code. La segunda opción es descargar el archivo CSV directamente en el cuaderno de Google Colab.
Para simplificar el proceso, aquí utilizaremos el segundo método y cargaremos el archivo directamente en el cuaderno. Copia el bloque de código que aparece a continuación y ya habrás cargado con éxito tu primer dataframe de datos de los datos físicos de SkillCorner.
# importar los paquetes necesarios para trabajar con los datos
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
url = "https://raw.githubusercontent.com/SkillCorner/opendata/master/data/aggregates/aus1league_physicalaggregates_20242025.csv"
df = pd.read_csv(url)
# visualizar las primeras cinco filas del dataframe, df
df.head()
3 - Normalizar los datos
Ya casi estamos listos para empezar a crear las visualizaciones, pero primero debemos realizar algunas operaciones finales de normalización y agregación de los datos.
El conjunto de datos contiene actualmente columnas como el total de minutos jugados y los recuentos brutos de las métricas a nivel de temporada. Para que estas métricas sean comparables entre los jugadores, debemos normalizarlas en función del tiempo de juego.
Esto se suele hacer utilizando los datos por cada 90 minutos en el campo (p90) o por cada 60 minutos de tiempo de balón en juego (p60 BIP). El enfoque p60 BIP es posible porque el conjunto de datos incluye los minutos jugados con el equipo en posesión de balón y sin ello (TIP/OTIP), lo que nos permite centrarnos específicamente en el tiempo de juego activo.
No todas las métricas requieren normalización. Algunas, como PSV-99 (velocidad máxima) o el tiempo para alcanzar la velocidad de sprint, representan rendimientos físicos máximos y, por lo tanto, utilizan el valor registrado más alto de cada jugador en lugar de un total.
# Filtrar a un mínimo de cinco partidos disputados
df = df[df['count_match'] >= 5 ]
# Normalizar las métricas por cada 90 minutos
df['hi_count_p90'] = (df['hi_count_full_all'] / df['minutes_full_all']) * 90
df['distance_p90'] = (df['total_distance_full_all'] / df['minutes_full_all']) * 90
# Normalizar las métricas por cada 60 minutos de tiempo de balón en juego
df['explosive_accels_to_sprint_p60'] = (df['explacceltosprint_count_full_tip'] + df['explacceltosprint_count_full_otip']) * 60 / (df['minutes_full_tip'] + df['minutes_full_otip'])
# Explorar las columnas/métricas en nuestro dataframe, df
df.columns.unique()
4 - Crear un gráfico de barras
Los gráficos de barras se encuentran entre las visualizaciones más utilizadas en el análisis futbolístico debido a su formato claro y eficaz. Permiten mostrar rápidamente las clasificaciones y comparar a los jugadores en función de una métrica concreta.
La visualización que se muestra a continuación presenta el ranking de los 10 jugadores con mayor índice PSV-99.
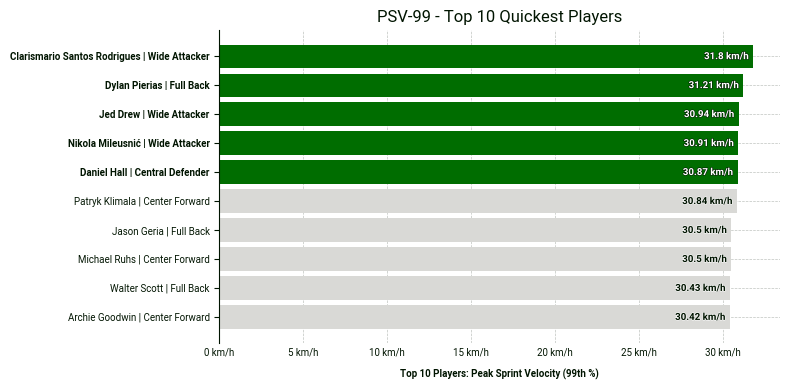
Copia el bloque de código que aparece a continuación para reproducir el gráfico en tu propio cuaderno.
# 1. Ordena por la métrica y selecciona los 10 primeros
# Utilizando <psv_99>, que es el nombre de la columna
top_10_physical = df.sort_values('psv99', ascending=False).head(10).copy()
# 2. Crear una etiqueta personalizada para el gráfico (Nombre | Posición)
# Esto combina el nombre del jugador y su posición en el eje Y
# This combines the player name and their role for the Y-axis
top_10_physical['plot_label'] = (
top_10_physical['player_name'] + ' | ' + top_10_physical['position_group']
)
# 3. Obtén automáticamente los ID de los 5 primeros para resaltarlos en verde
top_5_ids = top_10_physical['player_id'].head(5).tolist()
# 4. Crear el gráfico de barras
fig, ax = bar.plot_bar_chart(
df=top_10_physical,
metric='psv99',
label='Top 10 Players: Peak Sprint Velocity (99th %)',
unit='km/h',
primary_highlight_group=top_5_ids, # Estos cinco se mostrarán en verde
primary_highlight_color='#006D00', # La verde de SkillCorner
add_bar_values=True,
data_point_id='player_id', # Coincide con los ID de top_5_ids
data_point_label='plot_label', # Utiliza la etiqueta de 'Name | Position'
plot_title='PSV-99 - Top 10 Quickest Players'
)
5 - Crear un gráfico de radar
Nuestra biblioteca de visualización también incluye una plantilla para un gráfico de radar. En este caso, la hemos aplicado a nuestros datos físicos para obtener un resumen rápido del perfil físico de un jugador, pero la plantilla se puede adaptar fácilmente para mostrar diferentes combinaciones de métricas.
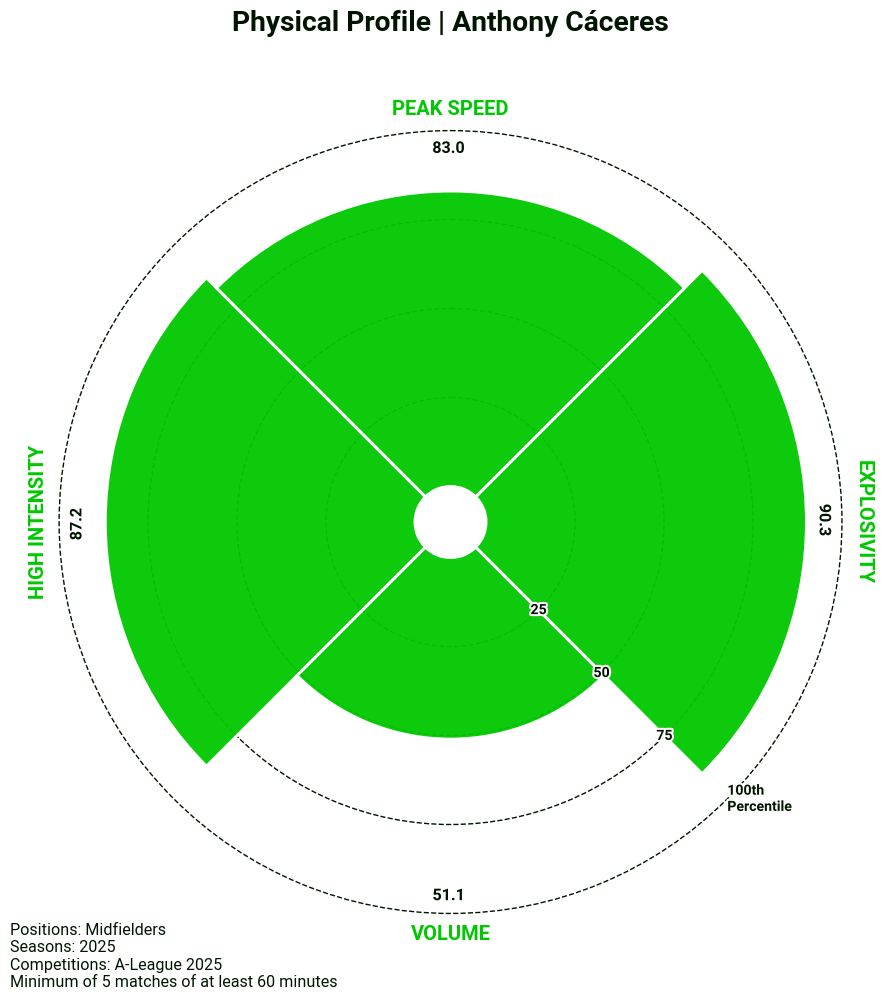
# 1. Filtrar a los centrocampistas
radar_df = df[df['position_group'] == 'Midfield'].copy()
# 2. Crear las categorías del radar
PHYSICAL = {
'hi_count_p90': 'High Intensity',
'psv99': 'Peak Speed',
'timetosprint_top3': 'Explosivity',
'distance_p90': 'Volume'
}
# 3. Crear las columnas de percentiles
radar_df['hi_count_p90_pct'] = radar_df['hi_count_p90'].rank(pct=True) * 100
radar_df['psv99_pct'] = radar_df['psv99'].rank(pct=True) * 100
radar_df['distance_p90_pct'] = radar_df['distance_p90'].rank(pct=True) * 100
# Invetir 'timetosprint_top3' (Menos tiempo = percentil más alto)
radar_df['timetosprint_top3_pct'] = radar_df['timetosprint_top3'].rank(pct=True, ascending=False) * 100
# 4. Asigna los valores percentiles a las claves originales para las etiquetasfor metric in PHYSICAL.keys():
radar_df[metric] = radar_df[f"{metric}_pct"]
# 5. Crear el gráfico de radar
fig, ax = rad.plot_radar(
radar_df,
data_point_id='player_name',
label="Anthony Cáceres",
plot_title='Physical Profile | Anthony Cáceres',
metrics=list(PHYSICAL.keys()),
metric_labels=PHYSICAL,
suffix='',
# Sample text info
positions='Midfielders',
matches=5,
minutes=60,
competitions='A-League 2025',
seasons='2025',
add_sample_info=True
)
Ir más alla
Si quieres ver otras formas de visualizar los datos, te animamos a que explores el cuaderno completo de Google Colab. El cuaderno contiene el código utilizado en esta publicación, junto con ejemplos de diagramas de enjambre y de dispersión de la biblioteca SkillCorner Viz Library que puedes explorar y adaptar a tus propios proyectos.
Siempre te animamos a compartir tu trabajo en las redes sociales. Si lo haces, por favor, cita a SkillCorner como fuente de los datos y etiqueta nuestra cuenta correspondiente en X/Twitter o LinkedIn.
En la próxima entrega de la serie, presentaremos las puntuaciones z y mostraremos cómo se pueden utilizar para estandarizar métricas e identificar valores atípicos estadísticos.
No te lo pierdas.